
はじめに
ChatGPT4oはより返答が人間の返答スピードに近くなり性能は従来のGPT4-turboに匹敵し、日本語のような非英語言語の性能向上が報告されています。 そこで前回に続き画像処理100本ノックを使用する。 ChatGPT4oがどれくらいのプログラミング能力、言語把握能力かを確かめていきます。
*以下はChatGPTによる返答のみを提示します。
Q.K-meansによる減色処理 (Step.1) 色の距離によるクラス分類
原画像

ChatGPT4o
プロンプト
K-meansによる減色処理 (Step.1) 色の距離によるクラス分類
アルゴリズムは,
画像からランダムにK個のRGB成分をサンプリングする。(これをクラスと呼ぶことにする。)
画像のそれぞれの画素に対して色の距離が最小となるクラスのインデックスを割り振る。
色の距離 dis = sqrt( (R-R’)^2 + (G-G’)^2 + (B-B’)^2)
各インデックスに対応する色成分の平均をRGBそれぞれに対して取り、新たなクラスとする。
元のクラスと新しいクラスが全く同じならK-meansを終了する。そうでなければ、新しいクラスを元クラスとして2-3を繰り返す。
元画像の各画素で色の距離が最小となるクラスのRGBを割り当てる。
ここでは1-2を実装せよ。
クラス数はk=5とする
ここでは画像をreshape((HxW, 3))にreshapeすると扱いやすくなる。
1においてはnp.random.seed(0)として、np.random.choice(np.arrange(画像のWxH), 5, replace=False)
まずは3-5のループを考えずに実装せよ
K-meansによる減色処理のステップ1と2を実装するために、以下のPythonコードを作成しました。ここでは、クラス数をK=5とし、画像データをreshapeして扱いやすくします。
まず、必要なライブラリをインポートします。
import numpy as np
import matplotlib.pyplot as plt
from skimage import io
# 画像を読み込み、HxWx3の形状にする
image = io.imread('your_image_path.jpg')
H, W, _ = image.shape
image_reshaped = image.reshape((H * W, 3))
# クラス数Kを設定
K = 5
# 乱数のシードを設定
np.random.seed(0)
# 画像からランダムにK個のRGB成分をサンプリング
random_indices = np.random.choice(np.arange(H * W), K, replace=False)
clusters = image_reshaped[random_indices]
# 各画素に対して色の距離が最小となるクラスのインデックスを割り振る関数
def assign_clusters(image_pixels, clusters):
distances = np.linalg.norm(image_pixels[:, np.newaxis] - clusters, axis=2)
return np.argmin(distances, axis=1)
# 各画素に対して最も近いクラスのインデックスを計算
assigned_clusters = assign_clusters(image_reshaped, clusters)
# クラスの割り当てを画像として表示
assigned_image = clusters[assigned_clusters].reshape((H, W, 3))
# 画像を表示
plt.imshow(assigned_image.astype(np.uint8))
plt.show()
このコードでは、次のステップを実装しています:
画像データを読み込み、(HxW, 3)にreshapeします。
クラス数をK=5と設定します。
np.random.seed(0)を設定し、画像からランダムに5つのRGB成分をサンプリングします。
各画素に対して色の距離が最小となるクラスのインデックスを計算する関数を定義します。
各画素に最も近いクラスのインデックスを割り振ります。
クラスの割り当て結果を元の画像形状にreshapeし、表示します。
出力結果

公式解答
import cv2
import numpy as np
import matplotlib.pyplot as plt
from glob import glob
# K-means step1
def k_means_step1(img, Class=5):
# get shape
H, W, C = img.shape
# initiate random seed
np.random.seed(0)
# reshape
img = np.reshape(img, (H * W, -1))
# select one index randomly
i = np.random.choice(np.arange(H * W), Class, replace=False)
Cs = img[i].copy()
print(Cs)
clss = np.zeros((H * W), dtype=int)
# each pixel
for i in range(H * W):
# get distance from base pixel
dis = np.sqrt(np.sum((Cs - img[i]) ** 2, axis=1))
# get argmin distance
clss[i] = np.argmin(dis)
# show
out = np.reshape(clss, (H, W)) * 50
out = out.astype(np.uint8)
return out
# read image
img = cv2.imread("imori.jpg").astype(np.float32)
# K-means step2
out = k_means_step1(img)
cv2.imwrite("out.jpg", out)
cv2.imshow("result", out)
cv2.waitKey(0)出力結果

コードの違い
形状変更やサンプリングはどちらとも同じだがクラスの割り当てから変わってきて、公式解答は手動での計算式を使用している。それに対してChatGPT4oはnp.linalg.normを使用して手動での計算式ではなくライブラリの公式を使用してのクラス割り当てを行っている。 出力結果が変わってしまった原因としてクラスの割り当て方法が異なった点が挙げられます。
なぜ公式解答と違ってしまったか
なぜ公式解答と同じクラスの割り当てを行わなかったかをChatGPTに聞いてみた。
|
ChatGPT
私の解答ではクラスのインデックスに基づいて色を再割り当てする方法を提案しましたが、これはグレースケールではなく、カラー画像で結果を表示する方法でした。以下にその理由を説明します。 理由
|
K-meansによる減色処理 (Step.2) 減色処理
ChatGPT4o
プロンプト
K-meansによる減色処理 (Step.2) 減色処理
アルゴリズムは,
画像からランダムにK個のRGB成分をサンプリングする。(これをクラスと呼ぶことにする。)
画像のそれぞれの画素に対して色の距離が最小となるクラスのインデックスを割り振る。
色の距離 dis = sqrt( (R-R’)^2 + (G-G’)^2 + (B-B’)^2)
各インデックスに対応する色成分の平均をRGBそれぞれに対して取り、新たなクラスとする。
元のクラスと新しいクラスが全く同じならK-meansを終了する。そうでなければ、新しいクラスを元クラスとして2-3を繰り返す。
元画像の各画素で色の距離が最小となるクラスのRGBを割り当てる。
ここでは1-2を実装せよ。
クラス数はk=5とする
ここでは画像をreshape((HxW, 3))にreshapeすると扱いやすくなる。
1においてはnp.random.seed(0)として、np.random.choice(np.arrange(画像のWxH), 5, replace=False)
3-5のループを考えて実装せよ
|
出力結果

公式解答
import cv2
import numpy as np
import matplotlib.pyplot as plt
from glob import glob
def k_means(img, Class=5):
# get shape
H, W, C = img.shape
# initiate random seed
np.random.seed(0)
# reshape image
img = np.reshape(img, (H * W, -1))
# get index randomly
i = np.random.choice(np.arange(H * W), Class, replace=False)
Cs = img[i].copy()
while True:
# prepare pixel class label
clss = np.zeros((H * W), dtype=int)
# each pixel
for i in range(H * W):
# get distance from index pixel
dis = np.sqrt(np.sum((Cs - img[i])**2, axis=1)
# get argmin distance
clss[i] = np.argmin(dis)
# selected pixel values
Cs_tmp = np.zeros((Class, 3))
# each class label
for i in range(Class):
Cs_tmp[i] = np.mean(img[clss == i], axis=0)
# if not any change
if (Cs == Cs_tmp).all():
break
else:
Cs = Cs_tmp.copy()
# prepare out image
out = np.zeros((H * W, 3), dtype=np.float32)
# assign selected pixel values
for i in range(Class):
out[clss == i] = Cs[i]
print(Cs)
out = np.clip(out, 0, 255)
# reshape out image
out = np.reshape(out, (H, W, 3))
out = out.astype(np.uint8)
return out
# read image
img = cv2.imread("imori.jpg").astype(np.float32)
# K-means
out = k_means(img)
cv2.imwrite("out.jpg", out)
cv2.imshow("result", out)
cv2.waitKey(0)出力結果
コードの違い
ChatGPT4oは質問されるたびに学習していくため解答のコードとほとんど同じになった。出力結果も同じ。step1を行った後のため学習したと考えられる。ほとんど同じだが前の問題でもそうだったように距離の計算がChatGPTはnp.linalg.normを使用して距離を一括計算し処理の高速化を行っている。しかし、公式解答では手動での計算となっている。 いくら学習をしたとしても時間のかかるようなコードは出力せずに楽で高速化を行うようなコードを出力している。
英語で質問した場合
ChatGPTの主要言語は英語です。そのため一番理解しやすい言語である英語で質問した場合出力結果は変わるのか、先ほどのQ91の結果を用いて日本語との比較を行います。質問内容はQ91の質問内容を英訳したものを使用します。
*コードのみを提示します *英訳にはDeepLを使用
プロンプト
Q.91. Color Reduction by K-means (Step.1) Classification by color distance
Subtract colors from imori.jpg using K-means.
In Q.6, the color reduction process was also treated in Q.6, but in Q.6, the colors were reduced to predetermined colors. In Q.6, the colors were reduced to predefined colors. Here, we use K-means to dynamically determine the colors to be reduced.
The algorithm is based on the following algorithm.
Randomly sample K RGB components from the image. (We call this a class.)
For each pixel in the image, it assigns the index of the class with the smallest color distance.
Color distance dis = sqrt( (R-R’)^2 + (G-G’)^2 + (B-B’)^2)
The average of the color components corresponding to each index is taken for each RGB to make a new class.
If the original class and the new class are exactly the same, K-means is terminated. Otherwise, repeat 2-3 with the new class as the original class.
Assign the RGB of the class that has the smallest color distance for each pixel in the source image.
Here, implement 1-2.
The number of classes is k=5.
Here, reshape the image to shape((HxW, 3)) to make it easier to handle.
In 1, np.random.seed(0), np.random.choice(np.arrange(WxH of image), 5, replace=False)
Implement the 3-5 loop without thinking about it first.
英語の質問結果
import numpy as np
import cv2
import matplotlib.pyplot as plt
# Load the image
image = cv2.imread('imori.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Convert to RGB
h, w, c = image.shape
# Reshape the image to (HxW, 3)
pixels = image.reshape(-1, 3)
# Number of clusters
k = 5
# Initialize random seed
np.random.seed(0)
# Randomly choose 5 pixels as initial cluster centers
initial_centers_indices = np.random.choice(np.arange(h * w), k, replace=False)
centers = pixels[initial_centers_indices]
# Function to calculate color distance
def color_distance(c1, c2):
return np.sqrt(np.sum((c1 - c2) ** 2, axis=1))
# Step 2: Assign each pixel to the nearest cluster center
def assign_clusters(pixels, centers):
clusters = np.zeros((pixels.shape[0],), dtype=int)
for i, pixel in enumerate(pixels):
distances = color_distance(pixel, centers)
clusters[i] = np.argmin(distances)
return clusters
# Step 3: Recalculate the new cluster centers
def update_centers(pixels, clusters, k):
new_centers = np.zeros((k, 3), dtype=float)
for i in range(k):
cluster_pixels = pixels[clusters == i]
if len(cluster_pixels) > 0:
new_centers[i] = np.mean(cluster_pixels, axis=0)
return new_centers
# K-means clustering algorithm
max_iter = 100
for _ in range(max_iter):
clusters = assign_clusters(pixels, centers)
new_centers = update_centers(pixels, clusters, k)
# Check for convergence
if np.all(centers == new_centers):
break
centers = new_centers
# Assign the final cluster colors to each pixel
final_pixels = np.zeros_like(pixels)
for i in range(k):
final_pixels[clusters == i] = centers[i]
# Reshape the result back to the original image shape
result_image = final_pixels.reshape(h, w, c)
# Convert to uint8 for display
result_image = result_image.astype(np.uint8)
# Display the original and result images side by side
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Original Image')
plt.imshow(image)
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title('K-means Color Reduced Image')
plt.imshow(result_image)
plt.axis('off')
plt.show()
# Save the result
result_image_bgr = cv2.cvtColor(result_image, cv2.COLOR_RGB2BGR) # Convert back to BGR for saving
cv2.imwrite('imori_kmeans.jpg', result_image_bgr)
print("Final cluster centers:", centers)出力結果
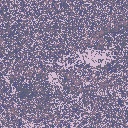
日本語の質問結果
K-meansによる減色処理のステップ1と2を実装するために、以下のPythonコードを作成しました。
ここでは、クラス数をK=5とし、画像データをreshapeして扱いやすくします。
まず、必要なライブラリをインポートします。
import numpy as np
import matplotlib.pyplot as plt
from skimage import io
# 画像を読み込み、HxWx3の形状にする
image = io.imread('your_image_path.jpg')
H, W, _ = image.shape
image_reshaped = image.reshape((H * W, 3))
# クラス数Kを設定
K = 5
# 乱数のシードを設定
np.random.seed(0)
# 画像からランダムにK個のRGB成分をサンプリング
random_indices = np.random.choice(np.arange(H * W), K, replace=False)
clusters = image_reshaped[random_indices]
# 各画素に対して色の距離が最小となるクラスのインデックスを割り振る関数
def assign_clusters(image_pixels, clusters):
distances = np.linalg.norm(image_pixels[:, np.newaxis] - clusters, axis=2)
return np.argmin(distances, axis=1)
# 各画素に対して最も近いクラスのインデックスを計算
assigned_clusters = assign_clusters(image_reshaped, clusters)
# クラスの割り当てを画像として表示
assigned_image = clusters[assigned_clusters].reshape((H, W, 3))
# 画像を表示
plt.imshow(assigned_image.astype(np.uint8))
plt.show()
このコードでは、次のステップを実装しています:
画像データを読み込み、(HxW, 3)にreshapeします。
クラス数をK=5と設定します。
np.random.seed(0)を設定し、画像からランダムに5つのRGB成分をサンプリングします。
各画素に対して色の距離が最小となるクラスのインデックスを計算する関数を定義します。
各画素に最も近いクラスのインデックスを割り振ります。
クラスの割り当て結果を元の画像形状にreshapeし、表示します。出力結果

やはりコードが少し変わって出力された。画像の読み込みが最初に行った日本語での質問の際はOpenCVを使用していたが英語で質問した際にはskimageのioモジュールを使用して画像を読み込みMatplotlibを使用して元画像と比較しながら出力される。rgb成分のサンプリング方法は変わらない。クラスターの割り当ての計算方法が日本語では個別に計算するコードが出力されたが英語では一括で計算するようなコードを出力しより簡潔にコードを書いている。出力結果は同じだがそれまでのアプローチの仕方が全く異なる方法でアプローチしている。出力が違う理由としては英訳した際に質問内容が少し変化してしまったことが考えられる。その結果出力が変わってしまったと考えられる。
まとめ
ChatGPT4oは、とても優秀で一度質問した内容については学習をして、次に似た問題を質問された際にはその学習を生かしさらに精度を高めて質問に答えてくれる。今回の場合は、アルゴリズムなどを説明したうえでプログラミングの解答を得たが、アルゴリズムを説明せずにプログラムの構想だけで質問した場合には、この精度が保たれるのか気になるところではある。 また、日本語で質問するよりも英語で質問したほうがより良い回答を得られることが分かった。 翻訳ツールなどあるので、日本語で書き起こし翻訳してあら質問してみると、より良い回答が得られる場合があるかもしれないのでぜひ試してみてください。


コメント
実験の結果を明確に比べられており面白かった。質問されるたびに学習していくというのは自分が利用するときにも参考になる点だった。
AIのミスに対して疑問を持ち、なぜそのようなミスが起きたのかを解明するのはとても面白いなと感じた。
この記事を読んでChatGPT4oの凄さを知ることができました。
学習速度の驚異的な速さには目を見張るものがあった。
検証結果が数度にわたって載っているのでChatGPTの回答がどのように変化していくのかが分かりやすかった
ChatGPTの出力精度の差違いについては気になっていた点であった為、非常に参考になった。
ChatGPTの活用方法やその学習能力の高さがしっかり分かり、ChatGPTが何を基準にプログラムを作っているかの考察もとてもいいと思いました
記事全体がとても見やすかったです。特にChatGPTの回答を吹き出しで表示することでわかりやすくなっている点が良いと思いました。
日本語で質問するよりも英語で質問した方がより良い結果が得られることは知っていましたが、実際に試したことはなかったので、知ることができて良かったです。